
Last reviewed and updated: April 17, 2026.
Kimi AI has evolved quickly, so Kimi K1.5 should now be presented as a historical and technical archive page, not as the current flagship Kimi model. Moonshot AI published the Kimi k1.5 technical report in January 2025 as an o1-level multimodal reasoning model trained with reinforcement learning, long-chain-of-thought methods, and long-context scaling up to 128K.
That positioning was important in early 2025. Kimi K1.5 showed how Moonshot could scale reinforcement learning for long reasoning traces across text, math, code, and vision tasks. However, it is no longer accurate to use this page as a current-product landing page for the newest Kimi experience. Today, Moonshot’s current official flagship direction is Kimi K2.5, a native multimodal model with text, image, and video input, 256K context, thinking/non-thinking modes, and agent workflows.
If readers want the newest official Kimi product experience, they should be directed to Kimi K2.5 and the official Kimi platform. This page should instead explain what Kimi K1.5 was, why it mattered technically, what its reinforcement-learning approach introduced, and where it fits in the Kimi model timeline.
Why Kimi K1.5 Is a Historical/Technical Page Today
Kimi K1.5 was a major 2025 research milestone, but it should not be framed as the current default Kimi model. Its best role on a modern Kimi site is to document the technical lineage behind later Kimi models.
The correct editorial framing is:
- Kimi K1.5 = historical reinforcement-learning and long-CoT milestone.
- Kimi-VL = later open-source vision-language milestone in the Kimi research line.
- Kimi K2 = 2025 open-weight MoE and agentic language-model milestone.
- Kimi K2.5 = current official flagship direction for multimodal, coding, and agent workflows.
This framing keeps the page useful for SEO around Kimi AI and Kimi while preventing contradictions with updated feature, comparison, and homepage content.
Historical Timeline: Where Kimi K1.5 Fits
| Date | Milestone | How to describe it now |
|---|---|---|
| January 2025 | Moonshot publishes Kimi k1.5: Scaling Reinforcement Learning with LLMs. | A research-focused multimodal reasoning release centered on long-context RL and long/short CoT performance. |
| April 2025 | The Kimi research line expands further with vision-language work such as Kimi-VL. | A separate multimodal open-source research milestone, not the same thing as K1.5. |
| July 2025 | Kimi K2 moves the Kimi family toward large-scale open-weight MoE and agentic coding workflows. | K2 should be treated as the next major model-line step after K1.5, especially for developer and agentic use cases. |
| January 2026 | Kimi K2.5 becomes the current official flagship direction. | Use K2.5 for current claims about modern Kimi capabilities, multimodal inputs, 256K context, and agent modes. |
What Kimi K1.5 Was Technically
Kimi K1.5 was presented by Moonshot as a multimodal large language model trained with reinforcement learning. Its technical report focused less on public product features and more on the training recipe that produced stronger reasoning behavior.
The core idea was that reinforcement learning could become a new scaling axis for LLMs. Instead of relying only on next-token pretraining data, the model learns to explore possible solution paths using rewards. Kimi K1.5 made that approach practical by combining long-context RL, long-chain-of-thought supervision, and infrastructure optimizations.
| Technical item | Kimi K1.5 historical summary |
|---|---|
| Model type | Multimodal LLM trained with reinforcement learning. |
| Primary research focus | Scaling RL for long-chain-of-thought reasoning. |
| Context length used for RL scaling | Up to 128K. |
| Modalities | Text and vision data were jointly used in the K1.5 training recipe. |
| Reasoning modes discussed | Long-CoT and short-CoT versions. |
| Optimization approach | A variant of online mirror descent, plus sampling strategy, length penalty, and data-recipe optimization. |
| Infrastructure idea | Partial rollouts to make long-CoT RL more efficient. |
| Best current page role | Historical/technical archive page inside the Kimi model family. |
This makes Kimi K1.5 valuable as a technical history page: it explains how Moonshot moved from long-context chat toward models that reason, plan, reflect, and correct over longer solution traces.
The Key Research Ideas Behind Kimi K1.5
The Kimi K1.5 report emphasized three technical ideas that still matter for understanding the Kimi model lineage.
1. Long-context reinforcement learning
Kimi K1.5 scaled the RL context window to 128K. The important insight was not just that the model could accept long prompts, but that longer reasoning traces could improve hard-problem performance. The report describes context length as a key dimension for continued RL scaling because longer contexts allow more planning, reflection, and correction inside the generated solution path.
2. Partial rollouts
Long reasoning trajectories are expensive to generate during RL training. Kimi K1.5 addressed this with partial rollouts: instead of regenerating an entire long response every time, the system can reuse portions of earlier trajectories and continue from stored segments. This makes long-CoT RL more computationally practical and helps prevent one extremely long trajectory from blocking the training system.
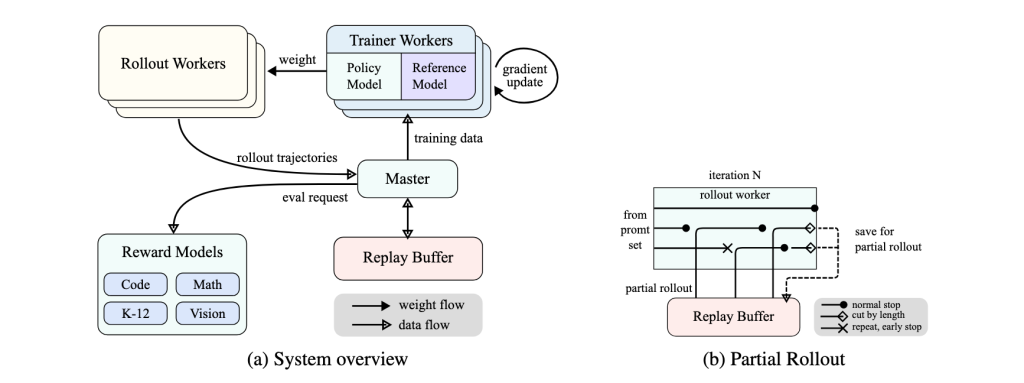
3. Improved policy optimization
The report also describes a reinforcement-learning formulation based on a variant of online mirror descent, improved through sampling strategies, length-penalty control, and data-recipe tuning. Moonshot highlighted that strong performance was achieved without relying on more complex systems such as Monte Carlo tree search, value functions, or process reward models.
Long-CoT and Short-CoT: The Main K1.5 Distinction
Kimi K1.5 should not be described as a single simple chat model. The technical report separates two important model behaviors:
- Kimi K1.5 long-CoT: optimized for longer reasoning traces and more expensive test-time computation.
- Kimi K1.5 short-CoT: designed to inherit reasoning improvements while using fewer tokens and producing shorter answers.
This distinction matters because many old pages describe “Kimi K1.5” as if all users were accessing the same mode. A more accurate historical page explains that K1.5 was a research system with both long reasoning and token-efficient short reasoning variants.
Historical Benchmark Snapshot
The benchmark numbers below should be treated as a historical snapshot from the Kimi K1.5 report. They are useful for explaining why K1.5 mattered in early 2025, but they should not be used to claim that K1.5 is the strongest current Kimi model today.
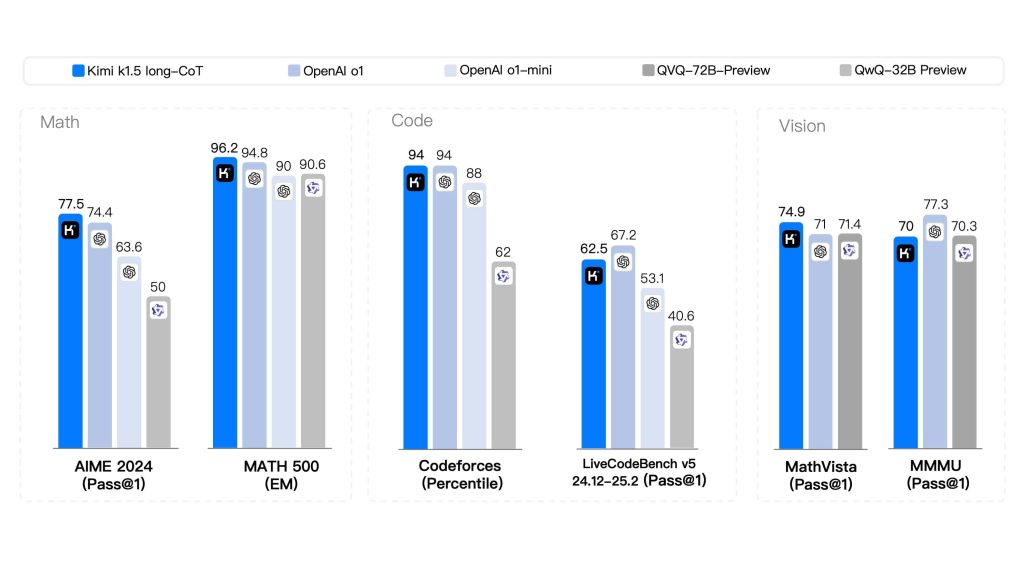
Kimi K1.5 long-CoT results
| Benchmark | Reported Kimi K1.5 long-CoT result | Why it mattered |
|---|---|---|
| MATH-500 | 96.2 | Strong mathematical reasoning result in the launch-era report. |
| AIME 2024 | 77.5 Pass@1 | Showed strong competition-math performance. |
| Codeforces | 94th percentile | Highlighted competitive-programming ability. |
| LiveCodeBench | 62.5 Pass@1 | Relevant for coding and algorithmic problem solving. |
| MathVista-Test | 74.9 Pass@1 | Showed multimodal visual-math reasoning. |
| MMMU-Val | 70.0 Pass@1 | Measured broader multimodal understanding. |
| MathVision-Full | 38.6 Pass@1 | Part of the report’s visual-reasoning evaluation. |
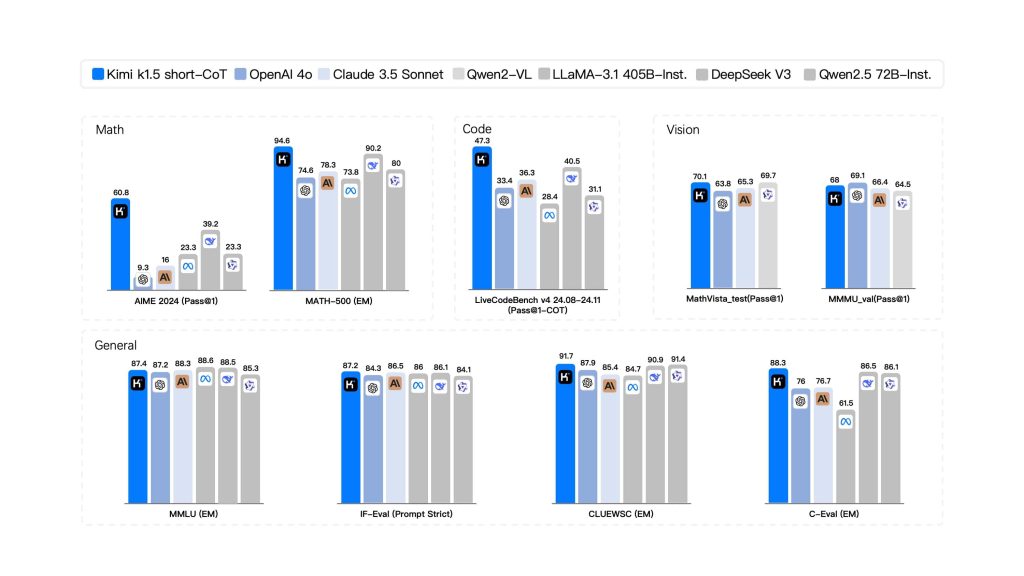
Kimi K1.5 short-CoT results
| Benchmark | Reported Kimi K1.5 short-CoT result | Why it mattered |
|---|---|---|
| MMLU | 87.4 | Broad general-knowledge performance. |
| IF-Eval | 87.2 | Instruction-following signal. |
| C-Eval | 88.3 | Chinese-language evaluation relevance. |
| MATH-500 | 94.6 | Strong short-answer math capability. |
| AIME 2024 | 60.8 Pass@1 | Token-efficient reasoning improvement over many short-CoT baselines. |
| HumanEval-Mul | 81.5 Pass@1 | Multilingual coding benchmark relevance. |
| LiveCodeBench | 47.3 Pass@1 | Historical signal for code reasoning. |
| MathVista-Test | 70.1 Pass@1 | Vision-language mathematical reasoning. |
What to Remove From the Old Page
The old version of this page used several claims that are risky or outdated in 2026. They should be removed or rewritten:
| Old claim type | Why it is risky | Better replacement |
|---|---|---|
| “Kimi K1.5 is the current developer model.” | Current official Kimi docs and product pages emphasize Kimi K2.5 and K2-family APIs. | “Kimi K1.5 was a 2025 research milestone. For current Kimi usage, check Kimi K2.5 and the official Kimi API docs.” |
Specific K1.5 API model names such as kimi-k1.5-preview. | API availability and model names change; this should not be published without current official documentation. | Remove the K1.5 API tutorial and link to current Moonshot/Kimi API documentation instead. |
| Claims about exact parameter count. | The K1.5 report does not provide a simple public parameter-count spec comparable to K2/K2.5 model cards. | Describe K1.5 by its training recipe, 128K RL context, and benchmark snapshot instead. |
| “Free/unlimited API” language. | Access policies, API billing, and rate limits are product-specific and change over time. | Use “check the official Kimi platform and API pricing pages for current access and billing.” |
| Claims that K1.5 is open-weight. | The official K1.5 repository is primarily a report repository; do not imply downloadable production weights unless a current official source says so. | Use “public technical report” or “research release” unless you are specifically citing a current checkpoint. |
How Developers Should Read Kimi K1.5 Today
Developers should read Kimi K1.5 as a technical reference, not as the best starting point for new integrations. The page is still useful because it explains the research ingredients behind later Kimi progress:
- Long-context RL: why a 128K context window mattered for reasoning training, not just long prompts.
- Long-CoT reasoning: how longer generated solution traces improved difficult math, code, and visual-reasoning tasks.
- Long2short training: how long-CoT behavior was used to improve shorter, more efficient model responses.
- Multimodal training: why K1.5 is part of the path toward later Kimi visual and agentic models.
- Infrastructure optimization: why partial rollouts, code sandboxes, and hybrid training/inference systems mattered for scaling.
For production API work, the safer recommendation is to consult the current Kimi Open Platform model list and use the model names currently documented by Moonshot. For the newest official model story, point readers to Kimi K2.5.
Kimi K1.5 vs. Kimi K2.5
A short comparison helps prevent confusion across the site:
| Aspect | Kimi K1.5 | Kimi K2.5 |
|---|---|---|
| Best page type | Historical/technical archive. | Current flagship model/product page. |
| Main contribution | Scaling reinforcement learning for long-chain-of-thought reasoning. | Native multimodal, coding, vision, and agentic workflows for real-world work. |
| Context | RL scaling up to 128K. | 256K for current K2.5 and several current K2-family API models. |
| Modalities | Text and vision in the research training/evaluation context. | Text, image, and video input in the current official API/product framing. |
| Modes | Long-CoT and short-CoT research variants. | Thinking/non-thinking at model level plus Kimi Web/App modes such as Instant, Thinking, Agent, and Agent Swarm. |
| Best use on this site | Explain the history of Kimi reasoning research. | Handle current claims about modern Kimi capabilities. |
Recommended Use Cases for This Historical Page
Because this page is no longer a current model landing page, it should serve these purposes:
- Model history: document the Kimi family’s transition from long-context reasoning to later agentic and multimodal systems.
- Technical education: explain long-CoT RL, partial rollouts, long2short training, and multimodal evaluation.
- SEO support: support the main Kimi AI keyword cluster without competing with current K2.5 pages.
- Internal linking: send readers toward Kimi K2, Kimi-VL, Kimi AI Features, and the current Kimi K2.5 official resources.
Official Sources Used for This Page
- Official MoonshotAI/Kimi-k1.5 GitHub repository
- Kimi k1.5 technical report on arXiv
- Official Kimi K2.5 API documentation
- Official MoonshotAI Kimi-VL Hugging Face model card
- Official Kimi K2.5 model page
- Official Kimi K2.5 technical blog
Want the latest official Kimi experience instead of the historical K1.5 research page? Visit the official Kimi platform for the current K2.5-based experience, or try Kimi-AI.chat for a lightweight text chat interface.
Kimi-AI.chat is an independent, unofficial website and is not affiliated with Moonshot AI. AI-generated outputs should always be reviewed before use. See our Disclaimer for details.